Trending - Additional Datasets
Trending datasets is supported through Data Import in Analyze.
For trending, additional datasets will need to be imported to an existing study family.
One requirement for trending is the datasets within the study family should all be structured similarly and intended for trending
(i.e. it actually makes sense to analyze two or more datasets together).
This page will cover features supported for Trending:
-
Adding an additional dataset
-
Automatic and manual mapping of questions between datasets
-
Limitations when modifying a question used in other datasets
Importing An Additional Dataset
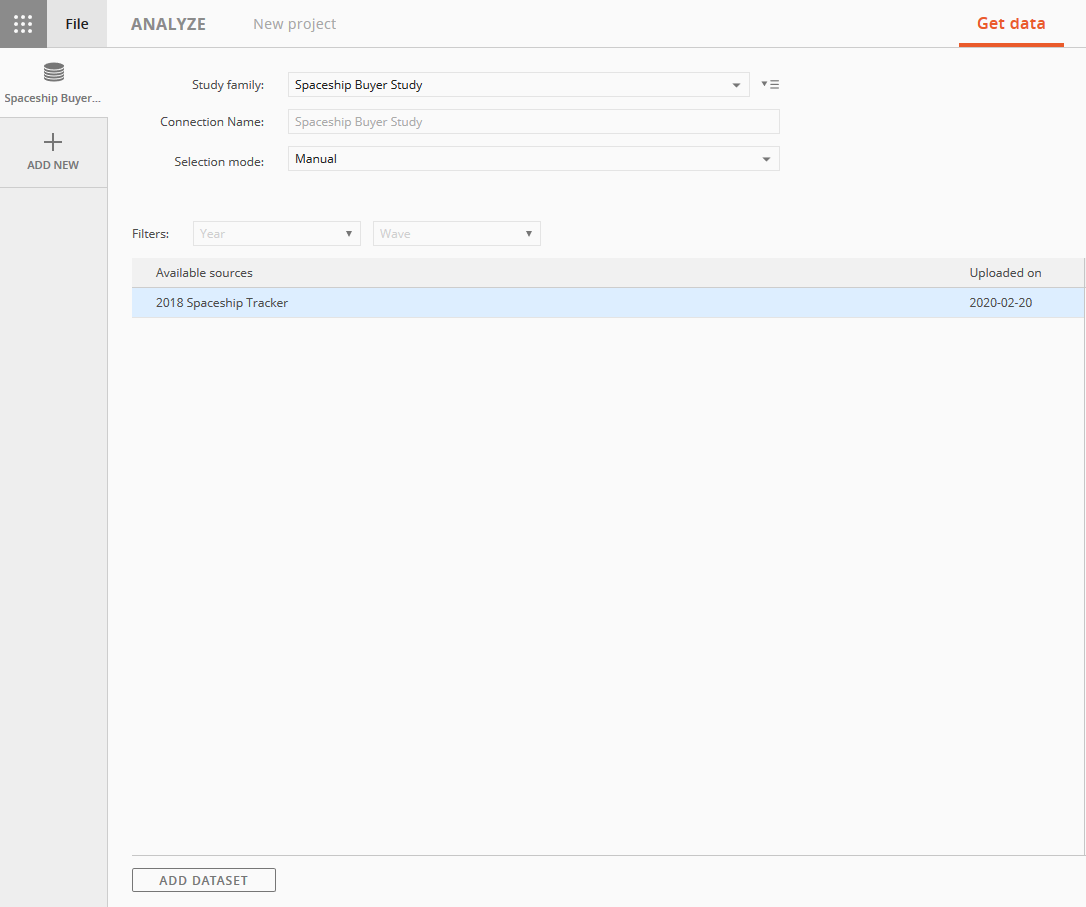
To import an additional data file into Analyze, select the study family that already includes at least one imported dataset.
Go to the Get Data in Analyze and select the existing study family to add the dataset.
At least one existing dataset will be listed in the Available Sources.
Click the Add Dataset button at the bottom of the page.
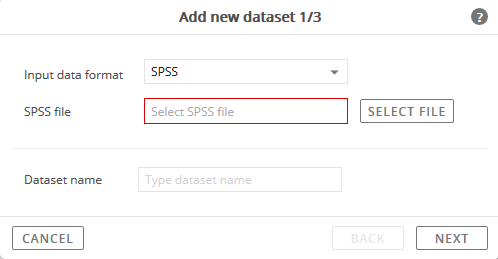
The Add New Dataset window will appear.
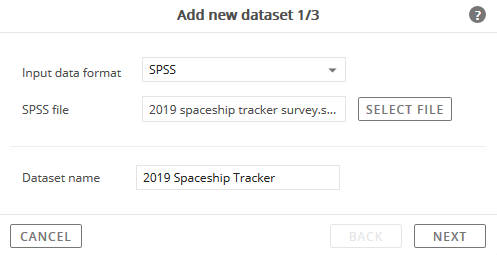
Click the Select File button to specify the data file to import.
Enter a name in the Dataset Name field.
This will be the name of the dataset. It will appear in the Available Studies list.
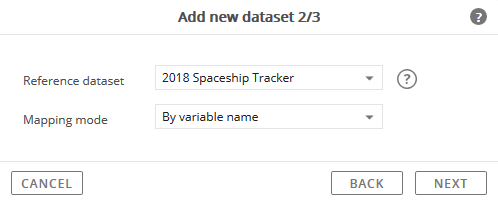
Click Next to proceed with specifying the reference dataset and method for mapping variables.
Import will automatically establish references between the existing dataset and new data that is being imported.
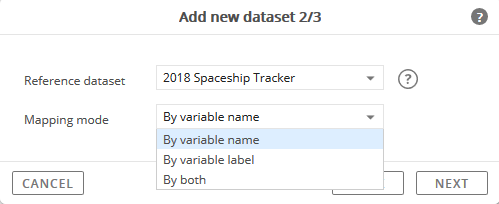
Select a Reference Dataset.
In terms of the data structure and setup, which existing dataset is most similar to the data file that is currently being imported?
The dataset selected here will be used as a blueprint to build an initial mapping of variables between the newly imported dataset and the existing items in the datasets already included in the study family.
The more similar the reference dataset is to the data file that is currently being imported, the fewer adjustments and less manual work will be required to produce a consistent data structure and mapping for all datasets of the study family.
If there is more than one dataset already in the study family, each of those datasets will be listed as an option in this menu.
Tip: In general, assuming there have not been drastic changes to the structure in data files between year to year, the most recent dataset year to the data file being imported should be used.
(e.g. If the data file being imported is for the year 2019, and there are 2018, 2017, and 2016 datasets listed as options in the reference drop-down menu, select 2018 since it is the most recent to the year of the data that is being imported.)
Select the Mapping Mode.
This setting will tell the data import process what criteria to use when linking the variable references in the dataset and imported data file.
-
Uses the name of the variable (question ID) as the reference to match between the dataset and imported data file.
-
Uses the label of the variable (question label text) as the reference to match between the dataset and imported data file.
-
Uses both the name and label of the variable and the as the reference to match between the dataset and imported data file.
Variable Name (question ID) Variable Label (question label text)
Define the
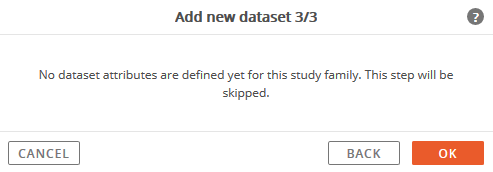
Study Family Attributes for the new dataset that is being imported.
If attributes were not defined for the study family, the following message will be displayed and this step will be skipped.
If attributes were defined for the study family, proceed with defining them for the imported dataset.
Enter the attribute criteria for the new dataset that is being imported.
Click OK to finalize the import process.
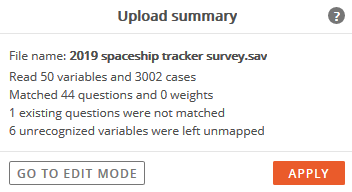
The upload summary is displayed after the dataset is converted.
The updated data file included:
-
6 unrecognized variables were left unmapped
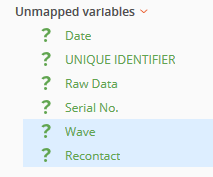
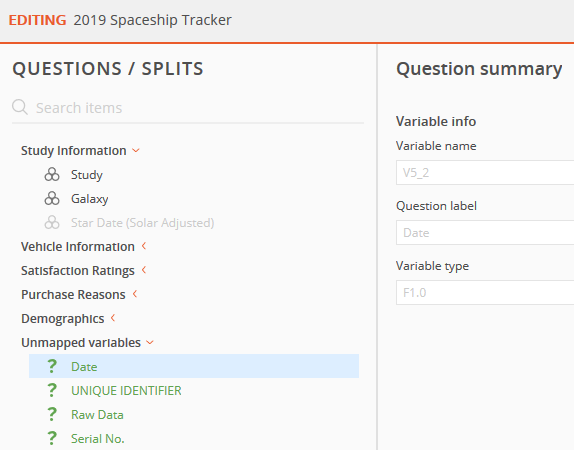
In Edit Mode, there will be a section named 'Unmapped Variables' that will include all the newly added variables, along with variables that the import process could not map.
-
1 existing question was not matched
This means that one existing question in the existing dataset structure could not be found in the newly imported file.
This will require further inspection. The most common cause for this is because the variable ID was changed in the data file.
If this is the reason, it can be resolved by manually matching the existing question to the new question.
The most common reason for this is because the data vendor changes variable IDs or label text.
Next, the new variables will need to be mapped to the dataset, along with addressing the 1 existing question that was not matched.
Proceed to Edit Mode, by clicking the Go To Edit Mode button.
The dataset can also be finalized and viewed in Analyze before editing by clicking the Apply button.
Manually Adding New Questions To The Dataset
New variables appear in the Unmapped Variables section because there is no existing reference to the previous dataset.
Any variables that were 'disconnected' in the other datasets will also appear in this section.
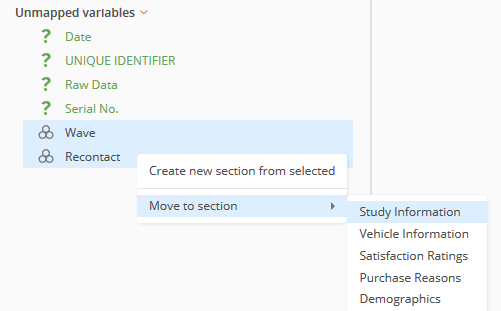
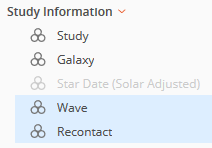
In this example, 'Wave' and 'Recontact' are new questions that need to be mapped and included in the dataset.
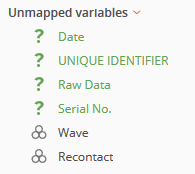
To add new variables as questions to the dataset, select them then click the Create Question button at the bottom of the page.
The icon and font color will change from the green question mark icon to black font and the category (or numeric) icon.
The newly added questions can be moved to their appropriate section.
Limitations When Modifying A Question Used In Other Datasets
The following modifications are supported when working with questions that are used in other datasets:
-
Question label changes (text changes)
-
-
Moving questions to a different section
-
-
Changing the order of question or sections
-
Merging separate questions into a multi-choice question
The following modifications are prohibited when working with questions that are used in other datasets:
-
Changing the question type when it is mapped to other datasets
(e.g. changing a category question to a numeric question)
Manually Matching An Existing Question To The Dataset
When working with separate data files over time, sometimes the variable names or IDs for existing questions might get changed between the previous data file and the new one.
The question structure and contents are consistent, but the inconsistencies in variable name (variable ID) or variable label (question label text) cause a mismatch between the dataset mapping structure and newly imported dataset.
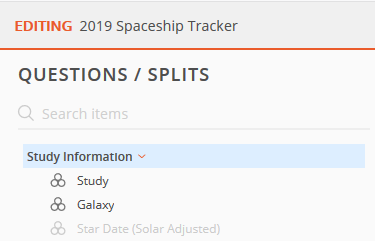
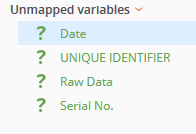
When this happens and the import process does not automatically find a match in the dataset for existing questions, that existing question will appear in a light gray font to indicate it is now missing in the newly imported dataset.
The Question ID from the old file: The Variable name from the new file:
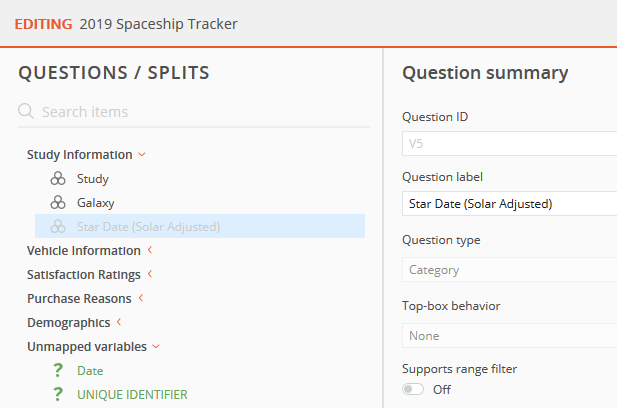
The date variable was named 'V5' in the data file. The date variable is named 'V5_2' in the data file.
The question name was 'Star Date (Solar Adjusted)'. The question name is 'Date'.
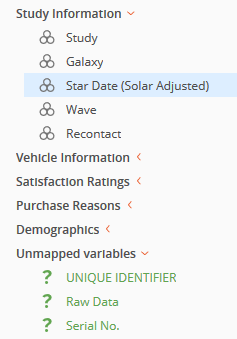
In this example, the mapping between the existing question in the dataset structure, 'Star Date (Solar Adjusted)' was broken in the newly imported dataset because the variable name and label were changed.
Since the date variable in the newly imported dataset is referred to as 'Date', it is being treated as a new question that needs to be mapped and included in the dataset.
This is the reason it is included in the 'Unmapped Variables' section after the dataset was imported.
After confirming that question contents are the same between the existing datasets and the newly imported dataset, the 'Date' question can be mapped manually to the 'Star Date (Solar Adjusted)' question.
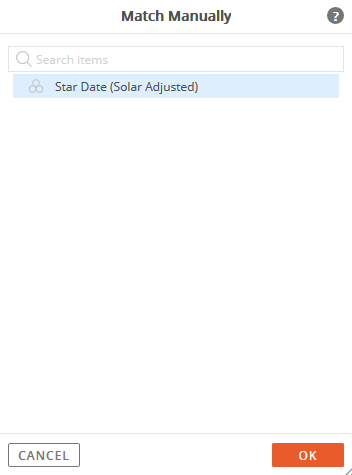
Select the question to match manually, then click the Match Manually button at the bottom of the page.
The Match Manually window will open and display possible question matches to choose from.
Select a question from the list (in some instances there may be only one to choose from), then click the OK button.
A match between the dataset and new data file is created. The question's status and font is updated. It no longer is displayed in light gray.
Confirm that there are no longer any new questions remaining in the 'Unmapped Variables' section.
If there are any questions still included in this section it's because they were previously 'disconnected' in the datasets and are meant to not be included when working with the datasets in Analyze.
Confirm the changes by clicking the Apply Changes button in the upper-right corner.
All edits will be reflected in the updated dataset in Analyze.