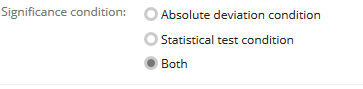
Based on combination of both conditions above (i.e. value is considered significantly different if both statistical test and absolute deviation conditions are satisfied)
Configuration of marking of significant differences is done as follows:
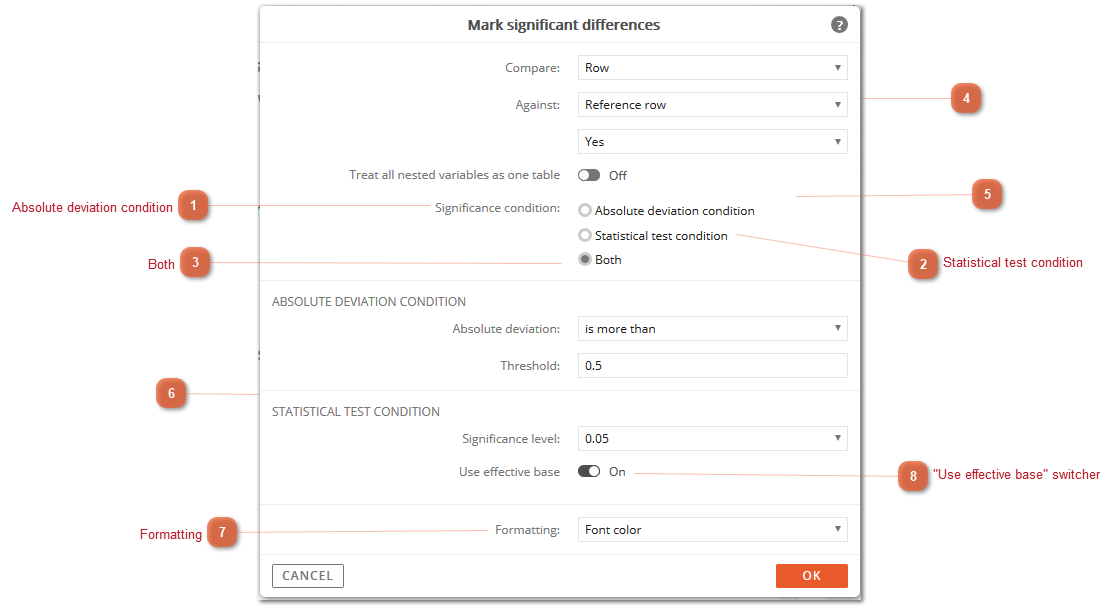
1. Choose the dimension in which the comparison is made (e.g. in rows or in columns)
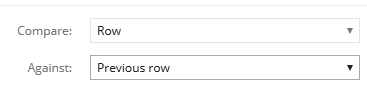
2. Choose the reference item. It can be either specific row/column (e.g. compare all values to Sample total, or compare all values to other make) or it can be previous row/column (useful for comparison over time, each period to previous). In case of nested rows/columns you can decide whether the reference row/column is a combination of all nested values, or the value at lowest level (default)
4. Finally, configure the exact comparison, depending on selected scenario and – in case of statistical procedure – on calculation type (for comparison of means you can choose between formula for Equal variances or Unequal variances, which is not applicable to test for proportions).
Weighting actually inflates the "number of answers" per respondents, at times by a relatively large factor. When performing significance testing, ideally, we wish to utilize the weighted data to capture the intent of the weighting. However, as significance testing is impacted by the scale of the weighted values, weighted significance testing can be impacted adversely by weighting, in particular in cases where weights represent large factors, say x10 or x100 or more.
In these cases, the effective base calculation can remove the influence of the numerically large weighted values while capturing the intent of the weighting. Basically, effective base is used as a safeguard against making statistical conclusions from a sample that has been drastically adjusted (using weights) to match target values like sales or population. From an analytical point of view effective base is to be calculated as sum(weight)^2/sum(weight^2).
If the data is weighted, we cannot use unweighted base and weighted percentages / mean scores at the same time, so that we do not use figures that come from two different worlds. On the other hand, weights themselves are not a good input for the statistical tests.
Let’s imagine the example below:
Respondent 1 - weight 100
Respondent 2 - weight 200
Respondent 3 - weight 100
Respondent 4 - weight 200
If you use such weights (they can be for example calculated based on sales data) you will see a lot of significant differences as the weighted sample size would be 600. At the same time effective base is 3.6 which is much more reliable. This way we can reduce the effect of very large weights.
NOTE: Differences based on absolute deviations are always available, for any calculation (regardless whether “from KPI” or “from question”). Differences based on statistical procedure are available for Means and Percentages (when calculation “from question”) or for specified statistics provided by KPIs, as long as the KPI definition contains needed information (because Analyze doesn’t know anything about the nature of calculations which are provided by a specific KPI, it is required that KPI definition is properly configured for statistical test).